Pending transactions on Custody API
Postmortem
In the past weeks, Tangany experienced a partial service disruption on the Custody API versions 1 and 2, impacting the execution of asynchronous operations and causing asynchronous operations (transaction execution, wallet creation) to remain in a `Pending` processing state for an unusually long time and often fail to complete.
We want to apologize to our customers for the severe disruption and express gratitude for their exceptional patience during the incident. Tangany takes full responsibility for the technical and operational shortcomings that led to this outage. We commit ourselves to continuously improving our services and reinforcing customer confidence in our products.
Description of the incident:
Asynchronous API operations (e.g., Blockchain transactions, wallet creations) do not start for multiple hours. Once started, transactions are likely to fail. One or multiple of the following symptoms occur:
- Asynchronous operations like transactions or wallet creations remain stuck for multiple hours with a `Pending` request status
- Transactions completed or failed mid-execution and reported runtime errors in the output or did not contain any output at all
- Transactions succeed on chain but do not reflect the correct status in the transaction request operation
Cause of the incident
Synopsis
Due to an undiscovered bug in the CSP runtime, an infrastructural constellation related to the software deployment of the Custody API led to a referencing problem causing issues resolving the payload location of message queues related to the execution of asynchronous operations.
Technical report
The incident was caused due to a poisoned-queue behavior from a special condition rooted in an undiscovered platform bug in the utilized serverless API runtime developed and managed by Tangany’s Cloud Service Provider (CSP). The asynchronous processing within the Custody API is based on a cluster of messaging queues located within a CSP storage hub service that manages async operations throughout the API life cycle. Each queue holds and dispatches control messages to build, execute and monitor blockchain transactions and other asynchronous software operations. These messages contain runtime data crucial to the execution of the asynchronous operations as a JSON-formatted payload. Once a control message exceeds a size threshold (e.g., due to a large blockchain transaction or internal buffering mechanisms in the API), the control message payload gets offloaded to a capacity-optimized alternative location within the storage hub service, and the queue message gets assigned a reference to said location. Typically this design consideration of the API runtime does not cause harm and has an insignificant performance impact on the processing.
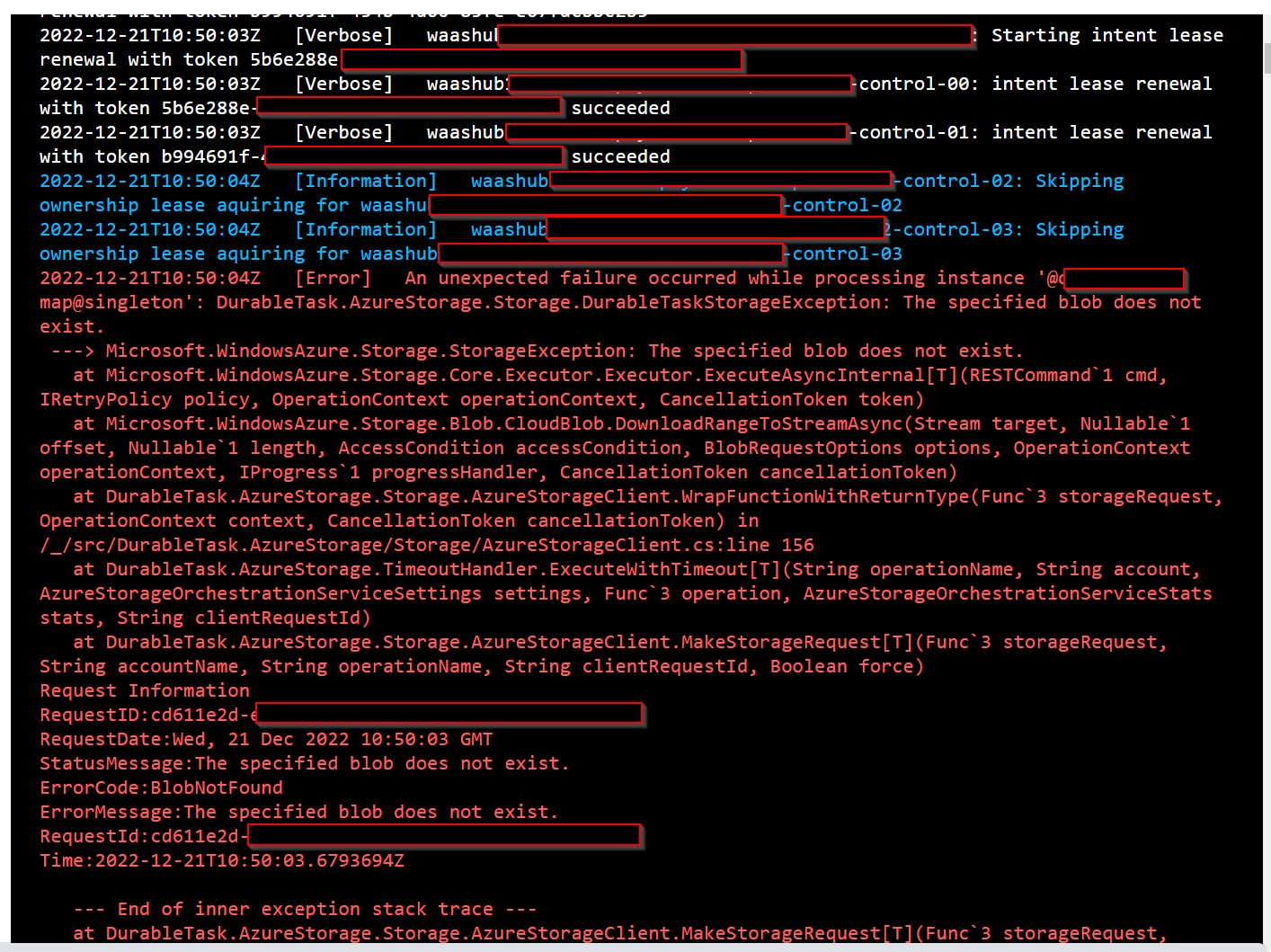 The Custody API utilizes a side-by-side deployment scenario based on a shared-resources model of specific queue and storage entities (e.g., the operation execution history table) designed to ensure zero-downtime software upgrade and failover capabilities. Despite being documented as a supported scenario by the CSP runtime docs, this specific constellation triggered the failed storage references and, over time, led to poisoning the impacted queue and all asynchronous operations managed by this queue. With the poisoning in effect, eventually, all queues become congested by this behavior, disrupting the asynchronous processing capabilities in the Custody API.
The Custody API utilizes a side-by-side deployment scenario based on a shared-resources model of specific queue and storage entities (e.g., the operation execution history table) designed to ensure zero-downtime software upgrade and failover capabilities. Despite being documented as a supported scenario by the CSP runtime docs, this specific constellation triggered the failed storage references and, over time, led to poisoning the impacted queue and all asynchronous operations managed by this queue. With the poisoning in effect, eventually, all queues become congested by this behavior, disrupting the asynchronous processing capabilities in the Custody API.
After a technical investigation by the CSP development teams, this detrimental behavior was confirmed as an undiscovered design flaw and confirmed as the root cause of the ongoing issue.
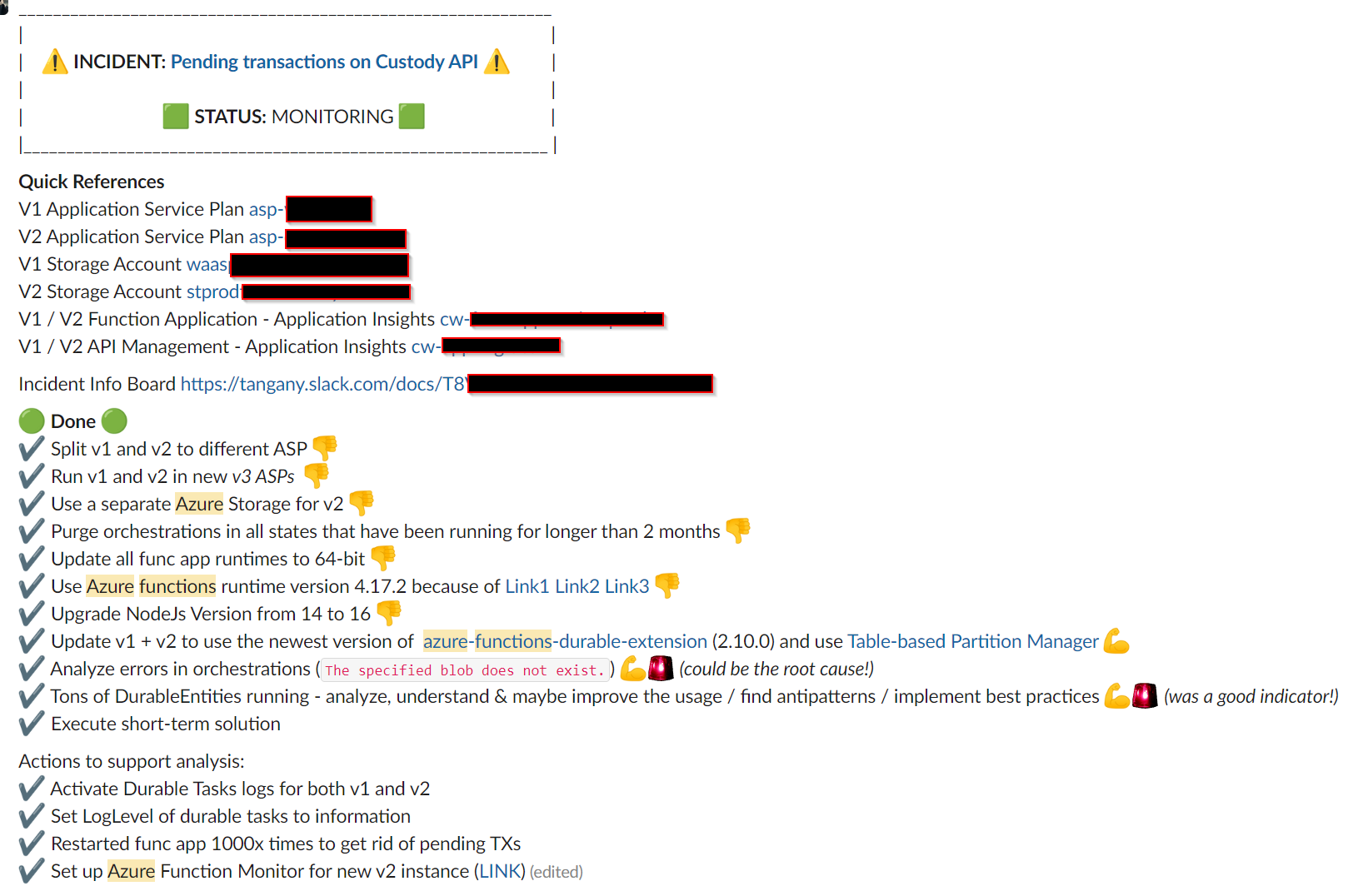
Taken actions
In summary following actions were taken during the course of the incident to counteract the symptoms and to discover and solve the incident’s root cause
- Deploying failover API backend instances. This measure allowed us to take impaired API backend instances from productive rotation and initiate close runtime analysis
- Restarting the API backend to resume stuck asynchronous operations. Over time we became aware that this was a temporary remedy with declining effectiveness
- Upgrading the platform, extending computing resource allocation, and scaling-up cluster instance (ASP) of the API backends to eliminate any resource-related bottlenecks leading to stuck operations.
- Supply software hotfixes to the API backend based on root cause assumptions. Multiple hotfixes were implemented and deployed during the course of the incident that changed and upgraded dependencies around the API runtime and infrastructural storage and queuing resources. Each hotfix deployment was closely monitored to evaluate potential improvements.
- Contacting the Cloud provider API runtime developers (CSP runtime developers) to analyze and confirm a suspected software bug in the API runtime. Request a short-term infrastructural workaround and a long-term software fix in the API runtime.
- Purging stuck operations and cleaning up the execution history state of the async operations storage hub.
- Establishing a monitoring dashboard for issues connected to the asynchronous processing and stuck operations (among others). Updated incident-managed processes based on the monitoring data.
- An internal board was set up to manage the incident. Regular war room meetings were held to analyze the incident and track the remediation process
Preventive measures:
- (Completed) Requested a root cause bug fix from the CSP runtime development team. We expect this fix to be released in the coming weeks.
- (Completed) Until then, Tangany maintains an infrastructural constellation of the Custody API backends that is confirmed not to trigger the root cause of the incident
- (Completed) Established relations with the CSP runtime developers in order to get fast responses on technical issues connected to the CSP runtime
- (In Progress) Introduce additional alerts and monitoring dashboards to detect suspicious transactions faster (within 15 mins)
- (Planned) Introduce emergency processes to failover Custody transaction handling independent of the underlying technical stack
Besides the imminent preventive actions concerning the incident, Tangany commits to a plan towards improving the availability and resilience of its software services to achieve industry-leading standing. We will follow up on these plans in a separate publication.
Time table
The technical issue that led to the incident manifested multiple times since the beginning of June and was first observed on Jun 14 2023, 18:32 CEST. Tangany resolved the incident on Jul 23 2023, 09:56 CEST.
Following is a timetable of the incident events.
 Jun 14 2023, 17:05 CEST: Incident team receives first automated alert about accumulated occurrences of "Pending" transactions
Jun 14 2023, 17:05 CEST: Incident team receives first automated alert about accumulated occurrences of "Pending" transactions
Jun 14 2023, 18:32 CEST: Begin of the first wave of stuck asynchronous operations on the Custody API. Begin the technical investigation
Jun 15 2023, 00:35 CEST: Start of the first wave
Jun 15 2023, 10:20 CEST: Internal acknowledgment of stuck operation. Start of the technical investigation
Jun 18 2023, 18:20 CEST: End of the first wave
Jun 26 2023, 16:07 CEST: Restarting Custody API backends throughout the day to resume stuck operations
Jul 7 2023, 13:35 CEST: Start of the second wave
Jul 11 2023, 10:26 CEST: Deployment of a hotfix-1 Custody API (v1) instance as initial failover backend
Jul 11 2023, 17:30 CEST: End of the second wave
Jul 12 2023, 10:38 CEST: Deployment of a hotfix-0 Custody API (v2) instance using an updated networking configuration and ASP, including changes to the storage hub service configuration
Jul 12 2023, 17:58 CEST: Extended application logging on the hotfix-0 Custody API (v2) instance
Jul 13 2023, 17:37 CEST: Initiated support case with the CSP helpdesk to investigate long-running asynchronous operations in Tangany Custody APIs
Jul 14 2023, 15:24 CEST: Deployment of a hotfix-2 Custody API (v1) instance using an updated networking configuration, upgraded ASP and updated API runtime dependencies
Jul 14 2023, 15:35 CEST: Start of the third wave
Jul 17 2023, 14:30 CEST: Contacted CSP helpdesk. Support confirmed that the API runtime is causing issues with stuck orchestrations. Investigation of the provided possible root causes by Tangany
Jul 18 2023, 10:00 CEST: Upgraded the cloud provider support plan and escalated the support case to critical severity. Invoked the CSP
Jul 18 2023, 10:15 CEST: Contacted CSP runtime developers with an in-depth report of our internal investigation requesting support and a API runtime bug fix
Jul 18 2023, 23:20 CEST: CSP runtime developers pinpoint an issue with the runtime partition management causing stuck async operation. Further analysis of Tangany backend instances by the CSP development team
Jul 19 2023, 08:00 CEST: Forwarded additional data to the CSP runtime developers for the investigation
Jul 19 2023, 15:01 CEST: Deployment of a hotfix-1 Custody API (v2) instance using alternative storage and queue partitioning approach and upgrades of runtime dependencies
Jul 19 2023, 17:24 CEST: Deployment of a hotfix-3 Custody API (v1) using alternative storage and queue partitioning approach and upgrades of runtime dependencies
Jul 19 2023, 21:00 CEST: The CSP developers identified a poison-queue root cause
Jul 19 2023, 22:12 CEST: Removing poisoned queue messages from the storage hub to temporarily redeem the incident issue
Jul 20 2023, 01:07 CEST: Identification of infrastructural causes leading to the queue poisoning by the CSP developers
Jul 20 2023, 13:00 CEST: Requested additional escalation of the CSP helpdesk case
Jul 20 2023, 17:58 CEST: Implementation of identified infrastructural short-term fix to prevent further queue poisonings. Purging remaining poisoned queue messages
Jul 20 2023, 18:20 CEST: End of the third wave. Initiating long-term monitoring of asynchronous processes and queues
Jul 21 2023, 09:06 CEST: Discussing details with CSP runtime developers toward a software patch and confirming Tangany’s current short-term infrastructural fix
Jul 21 2023, 15:07 CEST: Lifting the incident status due to clean logs after infrastructural fix
Jul 24 2023, 18:00 CEST: Confirmation of an API runtime bug by the CSP development team
Jul 26 2023, 18:00 CEST: Publishing the incident report
Resolved
Incident Status: We were able to pinpoint the issue and the root cause of the issue has been eliminated. After analyzing the system behavior for more than 24hr, it is stated that the Custody API service is stable and systems are back to their optimum performance. We closely monitor our runtime logs and expect the closure of the incident soon.
The issue has been resolved. We apologize for any inconvenience and really appreciate your cooperation.
Kindly find the below summary.
Issue start time: 08:00, 10 July 2023 Monday CEST
Issue resolution time: 10:00, 20 July 2023 Thursday CEST
Severity: High
Impacted Services: Custody API
Root cause: The incident was caused due to a poisoned-queue behavior from a special condition rooted in an undiscovered platform bug in the API runtime software.
Recovery: We identified the conditions that led to this behavior and arranged an application setup in which the condition does not trigger. Our engineering team is investigating the next steps for future API deployments that will prevent such erroneous constellation. We are also requesting a software fix from our platform provider as a long-term solution.
We will publish a detailed incident post-mortem shortly after confirming the incident closure.
Update
Below are the details of the upgrade, meanwhile, we are still monitoring our services in all aspects.
We will update some more latest developments here soon.
1- Optimization of multi-task hubs processing
2- Optimization of container handling
3- Change Func app orchestration processing
Update
We will update some more latest developments here soon.
1- Upgrade application computing environment
2- Optimize execution history buffer
3- Upgrade impacted software runtime
4- Change async orchestration partitioning logic
5- Deployed new API version
Update
Update
Thank you for your patience and cooperation.
Update
Thank you for your patience and cooperation.
Update
Thank you for your patience and cooperation.
Update
We apologize for any inconvenience and will keep you updated with the latest progress.
Activity start time: Fri, 14 Jul 2023 10:00:00 UTC
Monitoring
Identified
We apologize for any inconvenience.
Activity start time: Wed, 12 Jul 2023 13:00:00 UTC
Activity End time: Fri, 14 Jul 2023 13:00:00 UTC
Next update: TBD
Monitoring
As of now, services have been restored. We will keep monitoring till the assurance of optimum performance.
Activity start time: Tue, 11 Jul 2023 15:00:00 UTC
Activity End time: Wed, 12 Jul 2023 03:00:00 UTC
Monitoring duration: 6-12 hrs
Identified
Activity start time: Tue, 11 Jul 2023 06:00:00 UTC
Activity End time: Tue, 11 Jul 2023 15:00:00 UTC
Next update: TBD
Investigating
We are investigating the root cause of this and we will keep you posted.
We are sorry for the inconvenience this has caused.